I don’t think this follows. It’s akin to saying that any tasks which don’t share any mutable state with their parents (e.g. via actors or Sendable types) should not be cancelled.
2 Likes
This is the distinction I was trying to draw: process and tasks are fundamentally different. One is a construct defined by Swift structural concurrency, which concerns undefined behavior due to overlapping exclusive/exclusive or exclusive/non-exclusive accesses within a process; one is the process itself, which is out side of realm of swift structural concurrency (most likely outside of Swift itself too since Subprocess launches any process, not just processes written in Swift). Therefore I disagree with the comparison here.
It's okay for us to decide that functionally and conceptually speaking it makes the most sense to terminate the subprocess when the parent process goes out of scope for this API. I'm simply disagreeing with the notion that "this should be done because Swift structural concurrency dictated so"
2 Likes
There's a strong analogy here to regular processes and daemons, or Task and Task.detached, etc - lots of precedence in comparable systems for supporting both modes, because there's plenty of very good use cases for each.
The safer default is to cancel the subprocess when the controlling task / job / actor / whatever terminates. If that's not the intended behaviour, it's more likely to be discovered during testing than the converse, and it's less likely to cause abandoned, resource-wasting processes.
This behaviour could be selectable via a parameter at initialisation time (Subprocess.run in your current design) or something done later (e.g. a detach method). Deferring the decision provides some flexibility; it supports cases where it's not known whether the subprocess should be cut loose until after some interaction with the subprocess.
It is potentially complicated, however, by the multiple layers - there's the question of what to do when the owning Subprocess goes away, but also when the owning process goes away.
5 Likes
I see three desirable behaviors on cancellation (when the process isn't "detached"):
- ignore any cancellation and wait for the process to terminate normally (same as never checking for cancellation inside a task).
- send a graceful termination signal (
SIGINT), same as hitting Control-C in the terminal, then wait for the process to terminate itself. - send a forced termination signal (
SIGKILL).
It seems to me graceful termination 2 would make a nice default as it gives a chance to the subprocess to clean up (temporary files, file locks, subprocesses of its own, etc.).
There's also situations where multi-phase kills are used. e.g. SIGINT or SIGTERM first to allow for graceful shutdown, followed by SIGKILL some 'timeout' later in case the subprocess hangs or otherwise fails to comply.
This can always be implemented manually by the user of Subprocess, but I do think it'd be nice if this capability were built-in.
5 Likes
I view it more like it’s the tasks responsibility to clean up its resource usage when cancelled. In this case that resource happens to be a process.
2 Likes
One important difference between a Task and a child process is that if the parent process crashes, all Tasks are implicitly terminated, but child processes are not. In the past, it’s been ruled out of scope for the Swift runtime to provide ways to clean up after crashed programs—if this is important, the system architecture is expected to include a separate watchdog process. Can one use Subprocess as proposed to build such a watchdog?
When a parent process exits, child processes are typically reparented to the root process by the kernel.
On Linux, you can also arrange for the kernel to SIGHUP the child when the parent dies. But we don't even need that, because we can signal the whole process group.
The PoC implementation and API already have provision for setting the process group and session, which allow for signals to be sent to the whole group. Therefore we could arrange for the API to terminate all the processes, including child processes.
Of course, there are limitations here, e.g. if the spawned parent process spawns child processes in exotic ways, also setting the process group and session manually.
I think that graceful shutdown—i.e. SIGTERM then SIGKILL after a time—should be default. If the API can be designed to accommodate evolving to this, then I think SIGKILL could be a short-term solution.
While it's not my position, I think opt-in is also defensible. However, while it's possible to use the closure-based API and manually add a withTaskCancellationHandler, I think this is a common enough thing that the API should offer some conveniences here to opt-in to process termination on task cancellation.
I think opt-out would be nicer.
See also some discussion here:
First, thanks for updating the pitch. Sending a SIGKILL to the child process is 100% the right thing to do by default.
I want to talk about this for a second because I personally don't believe this statement is true. Structured Concurrency provides means for developers to write a structured program where at any given point in time it is known what tasks are running and what resources are owned by what task. The structured task tree gives us a strong model to reason about what resource is tied to which node in the task tree and if a node terminates (aka a task finishes) all its resources are also freed.
When writing applications with this mental model it makes it tremendously easier to reason about the applications behaviour. An important part of this is cancellation which mandates "cooperative cancellation" that should lead to the termination of a task as fast as possible.
This is a quite common need in the containerised world and we have overhauled swift-service-lifecycle last year to introduce the concept of graceful shutdown which can be triggered via signals such as SIGTERM. Application code can then listen to graceful shutdown via the withGracefulShutdownHandler method and decide what is the right thing to do. This allows for multi-phase shutdown compared to the "terminate as fast as possible" behaviour that task cancellation expects.
I don't think Subprocess should expose customisable behaviour for the shutdown of the subprocess when its task gets cancelled but rather leave it up to the user to do the right thing when he wants to gracefully terminate the subprocess.
5 Likes
Yep, exactly. Under the proposal Subprocess.run is the owner of the process which makes the Task that awaits it the co-owner. Thus by cancelling the Task the process termination should follow.
If we had a different model (very similar to the old Foundation):
let process = Subprocess(executableName: "cat")
let running: RunningSubprocess = process.run()
let result: SubprocessResult = try await running.waitUntilExit(/* timeout? */)
Here cancellation only affects the waiting, not the process itself because the user is the owner of the process (not the Task). So the process lives "outside of" the concurrency.
So basically it boils down to: is the process something that runs within Swift (as in proposal) or parallel to it (old Foundation)?
3 Likes
Just wanted to quick chime in that the behavior of a spawned process outliving it's parent (and being reparented by the OS) is sometimes exactly what you want, so if the default behavior becomes "kill the child when the parent is terminated" it would be important to preserve an escape hatch for when you explicitly wanted the child process to outlive the parent and become an orphan.
2 Likes
(This post is quite long, you may want to read it on Github.)
I don't use Swift Concurrency in day-to-day work and I'm not exactly familiar with fork internals (I always used wrappers), but for fun I wrote this test repo. This is basically the Process from the old Foundation upgraded to async/await. It is very similar to Python asyncio.subprocess. I will refer to some parts of the code later, so just a gist how it works:
let process = try Subprocess(
executablePath: "/usr/bin/cat",
arguments: ["Pride and Prejudice.txt"],
stdout: .pipe
)
let s = try await process.stdout.readAll(encoding: .utf8)
print(s ?? "<decoding-failed>")
// In 1 expression:
let s2 = try await Subprocess(…).stdout.readAll(encoding: .utf8)
This will start the process, read the whole stdout, waitpid it (in the background) and then close the files. More interesting example would be:
let process = try Subprocess(executablePath: "/usr/bin/sleep", arguments: ["3"])
Task.detached {
try await Task.sleep(nanoseconds: 1 * second)
try await process.kill()
}
let status = try await process.wait()
assert(status == -9)
wait is just a synchronization point. Cancelling a Task that waits only cancels this wait and does nothing to the process. You can use process.terminateAfter(body:) if you need scoped lifetime - this is exactly the same thing as fileDescriptor.closeAfter(body:). More examples available here.
Now let's go back to the proposal.
waitpid
The proposal does not exactly specify how waitpid happens, so the only thing that I have is the proof of concept:
extension Subprocess.Configuration {
public func run<R>(…) async throws -> Result<R> {
// (…)
return try await withThrowingTaskGroup(of: RunState<R>.self) { group in
@Sendable func cleanup() throws { /* Close files */ }
group.addTask { waitpid(pid.value, &status, 0) }
group.addTask {
// Call the closure provided by the user. I removed uninteresting stuff.
try await body()
try cleanup()
}
while let state = try await group.next() {
// Get the 'result' and 'terminationStatus'
}
}
}
}
We have a blocking waitpid call on the cooperative thread. Tbh. even from the proof of concept I expected at least waitpid(WNOHANG) + Task.sleep() in a loop. I tried to start a few ffmpeg processes, and it didn't work.
Can the proposal at least mention that this is not how it will work in the real implementation?
I outlined a few solutions here with a link to CPython implementation.
IO - Chatty children
Imagine this scenario:
- Child process starts with
stdoutset to pipe - Child writes to
stdout - Child writes some more…
- Deadlock
How? Pipes are backed by a buffer, if nobody reads the buffer then write will wait until somebody does. This will deadlock with the waitpid and no reader.
The proposal does not mention this situation.
Though if we take the code from the proof of concept at the face value then as soon as the body finishes we will close the reading end of the pipe. This will SIGPIPE or EPIPE in the child. Well… you can't deadlock if you crash it first. Is that intended?
A more "human" approach would be to read all of the nonsense that the child writes and then waitpid. Or do it in parallel: 1 Task reads and the 2nd waits.
Python documentation explicitly warns about this situation for wait, that's why they recommend communicate for pipes.
Examples using the code from my repository (you can easily translate it to Python with Popen):
-
 deadlock - pipe is full and the child is blocked
deadlock - pipe is full and the child is blockedlet process = try Subprocess( executablePath: "/usr/bin/cat", arguments: ["Pride and Prejudice.txt"], stdout: .pipe, ) let status = try await process.wait() // Deadlock -
 works - we read the whole
works - we read the whole stdoutbefore waitinglet process = try Subprocess( /* cat "Pride and Prejudice.txt" */ ) let s = try await process.stdout.readAll(encoding: .utf8) let status = try await process.wait() -
works - it reads
stdout/stderrin parallel, so we do not deadlock on any of themlet process = try Subprocess( /* cat "Pride and Prejudice.txt" */ ) let status = try await process.readAllFromPipesAndWait() // 'communicate' in Python
IO - Pipe buffer size
On Linux you can use fcntl with following arguments:
F_GETPIPE_SZ- get pipe buffer sizeF_SETPIPE_SZ- set pipe buffer size; conditions apply
It may not be portable.
On my machine (Ubuntu 22.04.4 LTS) the default is 65536. This is a lot, but still not enough to store the whole "Pride and Prejudice". You can just cat the whole thing for testing.
In theory we could allow users to specify the size of the buffer. I do not know the use case for this, and I'm not sure if anybody will ever complain if we don't. Long time ago I discovered that the more advanced features you use, the more things break. Anyway, if we want this then remember to ignore EBUSY.
I played with pipes here to discover how they work, so you may want to check this out. Linux only.
IO - Blocking
In "IO - Chatty children" I promised that it will not deadlock. I lied.
Tbh. I do not understand everything in AsyncBytes, but:
buffer.readFunction = { (buf) in
// …
let bufPtr = UnsafeMutableRawBufferPointer(start: buf.nextPointer, count: capacity)
let readSize: Int = try await IOActor().read(from: file, into: bufPtr)
}
final actor IOActor {
func read(from fd: Int32, into buffer: UnsafeMutableRawBufferPointer) async throws -> Int {
while true {
let amount = Darwin.read(fd, buffer.baseAddress, buffer.count)
// …
}
}
func read(from fileDescriptor: FileDescriptor, into buffer: UnsafeMutableRawBufferPointer) async throws -> Int {
// this is not incredibly effecient but it is the best we have
let readLength = try fileDescriptor.read(into: buffer)
return readLength
}
}
I'm not exactly sure what try await IOActor().read(from: file, into: bufPtr) does. It does not matter, I will just skip it.
Anyway, we have fileDescriptor.read and Darwin.read on cooperative threads. This method blocks. So currently we have:
- Task1 does
waitpid - Task2 waits for
read
But when we read something it will unblock. Surely it will not deadlock. Right?
Right? ![]() …
…
Right? ![]() …
… ![]() …
…
…
- Task1 does
waitpid - Task2 waits for
read - Process writes to
stderr, fills the buffer and waits for somebody to read it
We are down 2 cooperative threads and we have a deadlock with the child process. Ouch…
Is there some prevention method for this? The proposal does not mention it. In the code we have "this is not incredibly effecient but it is the best we have" comment, but I do not know what it means.
A lot of people say that you should not block on the cooperative thread. I don't agree. I think you are perfectly fine with blocking (within reason…), and I would take it any day over over-engineered solution that does not work.
That said if we really wanted to over-engineer this:
-
Option A: Threads - spin a thread for every
read, then resume theContinuation. On cancellation (which we have to support!) just kill the thread.This is actually how
waitpidworks in my library. You start a process, I create awaitpidthread. Once the child terminates it sends the message toSubprocessactor which closes the files and resumeswaitcontinuations (btw. they support cancellation, this is not as trivial as one may think).Threads are expensive, but in theory you can just have 1 thread for all IO and just
pollthe files. You can even monitor termination with Linux pid file descriptors, which gives us 1 thread for all of theSubprocessneeds. -
Option B: Non blocking IO - this is what I do for IO. For files you open them with
O_NONBLOCK, for pipes you set it later (btw. there is race condition in there).Reads from an empty pipe return
EWOULDBLOCK/EAGAIN. In my implementation I just returnnilasreadByteCount, so that the user knows that nothing happened.If they really need to
readsomething then they can use poor-person synchronization and doTask.sleep. Tbh. this is exactly what I do when user callsreadAll. Is this the best thing ever? Not. But it does not block. It is cooperative. And it supports cancellation.Blocking writes also return
EWOULDBLOCK/EAGAIN, but it is a little bit more trickier, so read the POSIX docs. Writesn > PIPE_BUFmay drop user data. This is what the spec says, but it also list the solution:- we can implement it on our side, but this is OS specific; on Linux you just split in
PIPE_BUFchunks - or just go with Jaws/TopGear logic and let the users create a bigger pipe
- or just mention
O_NONBLOCKin documentation, and let the users deal with it
- we can implement it on our side, but this is OS specific; on Linux you just split in
At this point we arrive to (unsurprising) conclusion: Subprocess should be 100% Swift concurrency neutral: it does not block and it respects cancellation. The library that I wrote archives this in following ways:
waitpidis done in a separate thread:- when the process finishes naturally -> OS notifies the
waitpidthread SIGKILL-> our code sends signal -> child terminates -> OS notifies thewaitpidthread
- when the process finishes naturally -> OS notifies the
- all IO is done with
O_NONBLOCK
IO - posix_spawn_file_actions_adddup2
With this everything should… Not yet! We have an infinite loop!
public struct CollectedOutputMethod: Sendable, Hashable {
// Collect the output as Data with the default 16kb limit
public static var collect: Self
// Collect the output as Data with modified limit
public static func collect(limit limit: Int) -> Self
}
Why do I have to provide a limit (implicit 16kb or explicit)? I just want all! Is Int.max good for this? How about Int.min? -1? Tough luck: all of the will crash with SIGILL: illegal instruction operand.
Btw. what it the unit for limit? The proposal says: "By default, this limit is 16kb (when specifying .collect).". But in code we have return .init(method: .collected(128 * 1024)). Instead it should be limitInBytes or byteCount.
Anyway, you are miss-using the api. This works:
let (readEnd, writeEnd) = try FileDescriptor.pipe()
let buffer = UnsafeMutableRawBufferPointer.allocate(byteCount: 10, alignment: 1)
try writeEnd.close()
// When 'read' returns 0 it means end of the file.
while try readEnd.read(into: buffer) != 0 {
// Code here never executes!
}
This is an infinite loop:
let (readEnd, writeEnd) = try FileDescriptor.pipe()
let buffer = UnsafeMutableRawBufferPointer.allocate(byteCount: 10, alignment: 1)
let writeEnd2 = dup(writeEnd.rawValue) // <-- I added this
try writeEnd.close()
while try readEnd.read(into: buffer) != 0 {
// Infinite loop.
}
You are doing the 2nd one. With posix_spawn_file_actions_adddup2 you send the file to the child, but you also have it in the parent process. The rule is: as long as there is writeEnd open then the read will never return 0.
This combined with blocking reads means that our cooperative thread is down. But surely when the process exists it will unlock the thread? No. The writeEnd is closed after the body ends and we are inside the body. This is why everything should be async: still an infinite loop, but at least it is cooperative.
Anyway, you are supposed to close the child ends in the parent process. This is how in my implementation I can:
let s2 = try await Subprocess( /* cat "Pride and Prejudice.txt" */ ).stdout.readAll(encoding: .utf8)
It will read all, without any limits. We could allow users specify some limit, but it should be an option, not a mandatory api limitation.
IO - Default values
In proposal we have:
public static func run<R>(
…,
input: InputMethod = .noInput,
output: RedirectedOutputMethod = .redirect, // <-- here
error: RedirectedOutputMethod = .discard,
_ body: (@Sendable @escaping (Subprocess) async throws -> R)
) async throws -> Result<R>
redirect will create pipe. If the user forgets to read it (or they are not interested) we may deadlock when pipe buffer becomes full. Isn't discard a better default value?
let example1 = try await Subprocess.run(
executing: .named("ls")
) { … }
let example2 = try await Subprocess.run(
executing: .named("ls"),
output: .redirect
) { … }
In example2 you can clearly see that something is happening. The framework did not decide this for us. It was our own decision, and it is very visible to the readers.
Btw. discard writes to /dev/null. As far as I know you can get away with only 1 discard file with O_RDWR. This way you use less resources. May matter on servers.
AsyncBytes - Optional output props
public struct Subprocess: Sendable {
public var standardOutput: AsyncBytes?
public var standardError: AsyncBytes?
}
Those properties are only usable if we specified .redirect. Why does the positive path require optional unwrap with !?
try await Subprocess.run(
executing: .named("ls"),
output: .redirect
) { process in
process.standardOutput!.<something>
}
This ! is not needed. AsyncBytes should store FileDescriptor? and throw EBADF (or precondition) if we try to use it when the argument was not .redirect.
AsyncBytes - Read buffer
public struct AsyncBytes: AsyncSequence, Sendable {
public typealias Element = UInt8
public typealias AsyncIterator = Iterator
public func makeAsyncIterator() -> Iterator
}
The only thing we have here is AsyncIterator. What if I wanted to write a StringOutput type that deals with all of the String stuff in a Java style decorator fashion:
let stdout = StringOutput(process.standardOutput!, encoding: .utf8)
for await line in stdout.lines() {
…
}
I'm sure everybody knows how StringOutput internals would look like.
Why do I need to read byte-by-byte? Can't I just read the whole buffer of data? This just forces me to write the code that undoes what AsyncBytes did. It applies an abstraction (including its own buffering) that I have not asked for. And now we need 2 buffers: AsyncBytes one and the one where I gather my String.
StandardInputWriter - Call finish?
For StandardInputWriter proposal states:
Note: Developers must call
finish()when they have completed writing to signal that the standard input file descriptor should be closed.
Why?
We are basically racing the process against the user code (body argument).
- process finishes 1st - reading end of the pipe is closed ->
SIGPIPE/EPIPE, but this has nothing to do with closing the file - user code (
body) finishes 1st - can't we close it after? If the process is still running then it will get values from the buffer, and eventuallyread(…) == 0
I guess in theory we could have a subprocess that reads from the stdin in a loop, so if we do not close the pipe it will loop forever. But for this use case we require all of the users to call finish()?
Why is it called finish instead of close?
Why can't the Subprocess own the input? Is there any situation where the input outlives the Subprocess?
We could make it idempotent where the 1st close would set the FileDescriptor to nil (to prevent double-closing). Then the Subprocess would call close again, just in case the user forgot. This will make finish/close optional for the users. They can, but they do not have to.
I do not like APIs based on the "user has to remember to do X". At least back in the RxSwift times we had DisposableBag and forgetting about it was a compiler warning. Here we get nothing.
StandardInputWriter - Sendable args?
public struct StandardInputWriter: Sendable {
private let actor: StandardInputWriterActor
@discardableResult
public func write<S>(_ sequence: S) async throws -> Int where S : Sequence, S.Element == UInt8
@discardableResult
public func write<S: AsyncSequence>(_ asyncSequence: S) async throws -> Int where S.Element == UInt8
}
Those Sequences will go to the actor. Shouldn't they be Sendable? I get concurrency warning for try await Array(asyncSequence).
I think that any green-field project should enable StrictConcurrency by default. People may say something about false-positives, or that this feature is not yet ready. For me it caches bugs. And it creates the right mental model of how things work, so that we do not have to "unlearn" later.
IO - StandardInputWriter - write names
Bike-shedding: on FileDescriptor methods that take Sequence are called writeAll. On StandardInputWriter (which is a wrapper around a FileDescriptor) we have write.
Do we want more consistent naming?
IO - File ownership for close
@beaumont wrote:
Because .readFrom(:) and .writeTo(:) both take FileDescriptor I tab-completed my way into a footgun, by passing .standardInput, .standardOutput, and .standardOutput to input, output, and error respectively. This of course was silly for me to do, because they got closed after the process exited.
I was thinking about the same thing! But it may be a little bit more complicated:
- single
shouldCloseFilesswitch - as soon as you set it tofalseyou have to close ALL of the files by yourself. Obviously, it is really easy to forget to do so. - separate
shouldCloseper file - you have to remember which files you have to close, and closing them twice may be an error. So does forgetting it. I went this way in my implementation.
The real semantic that we are trying to express is: move = close, borrow = do nothing. If we ignore all of the enums and the overload explosion we would have:
func run(…, stdout: borrowing File, …) async throws -> CollectedResult
func run(…, closingStdout: consuming File, …) async throws -> CollectedResult
The consuming version would call the borrowing one and then close the file. Obviously deinit would not call close. It is the other way around: consuming func close() will end lifetime and deinit does nothing .
If we go back to reality (column wise):
| InputMethod | CollectedOutMethod | RedirectedOutputMethod |
|---|---|---|
| noInput | discard | discard |
readingFrom borrowing |
writeTo borrowing |
writeTo borrowing |
readingFrom consuming |
writeTo consuming |
writeTo consuming |
| collect | redirect | |
| collect(limit:) |
A lot of the overloads! And we can't use enum because we can't store borrowing. We can't use protocols, because move-only do not support them. But we can:
// For a second let's assume that FileDescriptor is move-only.
struct CollectedOutputMethod: ~Copyable {
private enum Storage: ~Copyable, Sendable {
case consuming(FileDescriptor)
case borrowing(FileDescriptor)
}
static func writeAndClose(_ f: consuming FileDescriptor) -> CollectedOutputMethod {
return CollectedOutputMethod(raw: .consuming(f))
}
static func write(_ f: borrowing FileDescriptor) -> CollectedOutputMethod {
// We can't copy a FileDescriptor, but we can copy its properties.
// It works as long as we do not try to close it.
let copy = FileDescriptor(<copy properties>)
return CollectedOutputMethod(raw: .borrowing(copy))
}
}
Some people may not like it because we are (de-facto) copying the move-only object. I think it is all about the semantic of move-only, not about being move-only. And the semantic is: call close to consume. In the borrowing branch we will never call close. It is kind of like in move-only smart pointers we can copy the pointer, but the contract says that we should also increment refCount. Copy is allowed it is all about the semantic.
Obviously this is not possible because FileDescriptor is not move-only as we have to be compatible with the old Foundation. This was a theoretical exercise, but maybe somebody has some solution.
IO - Closing error
I already mentioned it a few weeks ago, but to have everything in 1 place:
Currently even if the process terminated successfully (regardless of the status), but the closing threw an exception then:
- the parent process (aka. our code) will only get the file closing exception - even if the state of the world (for example database) has changed.
- other files will not be closed.
There is a possible double closing issue.
4 Likes
Signals - ESRCH
Should signals throw on ESRCH? In my implementation:
/// - Returns: `true` if the signal was delivered. `false` if the process
/// was already terminated.
@discardableResult
public func sendSignal(_ signal: Signal) throws -> Bool
Most of the time you send SIGKILL/SIGTERM. If the process is already terminated they do nothing. I'm not sure if this is an error that we need to throw. If you really need this information then you can check the Bool return.
Also, this is a race condition. You think that the process is running, you send SIGTERM, but in the meantime the process has terminated. Is this a reason throw?
Signals - Duplicate pid
I'm not exactly sure if I'm correct, but I think that after the process has terminated its pid is available for reuse. Same thing as FileDescriptors, but IIRC files guarantee the lowest value from the table, and pids do not.
So in theory:
- We start a process with closure
bodyargument - Process terminates
bodystill runs- OS reuses pid
bodysendsSIGTERM
Is this possible? Idk.
In my implementation after the waitpid thread finishes I set the actor Subprocess state to terminated(exitStatus: CInt). From now on all of the sendSignal calls will do nothing and return false (meaning that process was terminated).
Arguments - ExpressibleByStringLiteral
Proposal v2 has:
Ideally, the
Argumentsfeature should automatically split a string, such as "-a -n 1024 -v 'abc'", into an array of arguments. This enhancement would enableArgumentsto conform toExpressibleByStringLiteral, (…).
The split may fail if the String is malformed, and from what I see init(stringLiteral:) does not allow failures.
Arguments - QOL
Minor QOL stuff:
-
public init(_ array: [String], executablePathOverride: String)- canexecutablePathOverridebe made optional? In the most common usage this parameter will not be supplied. Is this the same as @beaumont asked? -
Arguments(CommandLine.arguments.dropFirst())- do we want this? Obviously user canArray(…).
Environment - init
I assume that there is no public initializer for Environment() because that would be ambiguous between:
- empty collection - Swift convention; for example
Array<Int>()means empty. inherit- which is what users really mean.
Maybe custom could be renamed to empty, this word already exists in Swift: Array.isEmpty.
Environment - strlen bug
Just in case it slips through a code review later: Subprocess.Configuration -> spawn -> createEnvironmentAndLookUpPath -> createFullCString:
let rawByteKey: UnsafeMutablePointer<CChar> = keyContainer.createRawBytes()
(…)
let totalLength = keyContainer.count + 1 + valueContainer.count + 1
For String:
createRawBytesdoesstrdup(string)keyContainer.countreturnsstring.count
Try this:
let s = "Łoś" // Polish word for moose
print(s.count) // 3 - number of grapheme clusters
print(strlen(strdup(s)!)) // 5 - number of bytes
Fun fact: my real-world name contains "ł". If create a directory using it (which 99% of users do) and put as a value in env then totalLength is incorrect as it treats 1 Character = 1 byte while "ł" is 2 bytes.
Ergonomic & documentation
Though, by far my biggest gripe with the proposal is (btw. we are 25k characters in):
- we have 6 overloads with 8 or 9 arguments each.
- all of the overloads start with the same arguments making it hard to see the difference
- some of the arguments are optional which basically mean more overloads.
This makes the code completion for Subprocess.run( useless.
Also, the documentation would be very long - around 50% of the proposal. We would require people to spend 20min on reading before they can use the API. Then they would use it and come back to the documentation to re-read it because there is no "progressive disclosure". There is just 1 method with multiple overloads.
Also, we have to attach (almost) the same documentation to each run overload. And given that most of the stuff is the same (prolog and everything from Executable up to PlatformOptions arguments) it will be hard for users to differentiate between different overloads.
To solve this we would put the documentation on the Subprocess type, but still it will be ~50% of the proposal with multiple paragraphs. You can't create link to a paragraph to help somebody on Stack Overflow.
Also, API is different from other systems/languages. You can't just google "linux kill process" because most of this is not applicable to the model presented in the proposal.
I like the old Foundation Process docs. They are way too short, but when I want to read about something I just click it in the left side-bar.
That's theory, in practice:
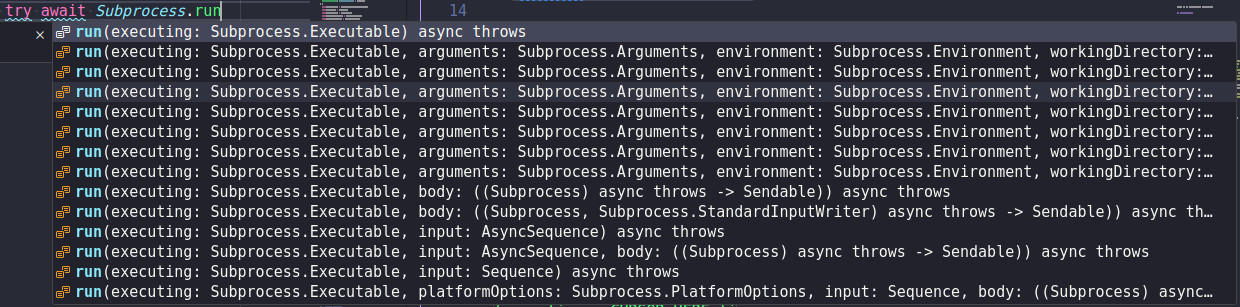
Q1: Which overload should we choose if we want to run git status?
let result = try await Subprocess.run(executing: .at("ls"))
Q2: Which run overload will this call? Will this open pipes for communication? Will this allocate buffer to collect output?
Answer 1: None of them. You have to copy an example from the documentation. Maybe if you are familiar with the API you just select randomly and remove all of the arguments you do not need. This is a bit of a made up scenario, because new users will never type Subprocess.run( they will try the initializer Subprocess( first, and then go to docs without trying anything else.
Answer 2: No closure -> this is CollectedResult call with .noInput. It will allocate buffers, so if this is not what you want then you just wasted some memory. Btw. there is a bug in the question that I asked: it should be .named("ls"). I think .atPath("ls") would make it easier to spot. Though it is still weird to read:
// Executing what? The subject is missing.
Subprocess.run(executing: .named("ls"))
// Proper sentence, but nobody is going to write it this way.
// In Poland we say: butter is butterish.
// It means: padding to make an essay longer just to pass length requirement.
Subprocess.run(executing: Executable.named("ls"))
// Different label.
Subprocess.run(executable: .named("ls"))
Ergonomic & documentation - Overhaul
(Section removed.)
SystemPackage.Errno
Swift system has a really nice Errno type that may simplify your implementation:
do {
let byteCount = try fd.read(into: buffer)
} catch Errno.wouldBlock, Errno.resourceTemporarilyUnavailable {
}
// Or:
internal func system_kill(pid: pid_t, signal: CInt) -> Errno? {
let result = kill(pid, signal)
if result == -1 { return .current }
return nil
}
They did a really good job, and I like it. I makes everything so much nicer to read/write. I also like their convention of system_ prefix for syscalls.
CustomStringConvertible
"\(Pid): \(executable) \(args trimmed to 20 characters)"
Or maybe the same as ps a -> COMMAND column.
Process outliving its parent
@jaredh159 (Jared Henderson) wrote:
Just wanted to quick chime in that the behavior of a spawned process outliving it's parent (and being reparented by the OS) is sometimes exactly what you want…
For my implementation I was thinking about adding Bool flag to disable termination tracking (waitpid thread). You can still do this: just start a process and never wait it. This ends parent and orphans the child.
I didn’t, because it is rather niche use case. Most of the time you want to spawn a daemon. This is platform specific. In practice I would just use one of the C templates that eventually calls Swift. So, at least for daemons, I think it is a non-issue. Do you have some other use case?
Not sure where the proposal stands on this. AFAIK old foundation can do this, but I have not tested it.
Overall proposal evaluation
Needs work.
5 Likes
In my case, I'm not spawning a daemon--it's probably fairly niche, but I was implementing a mechanism for a macOS app to relaunch itself (like how the Sparkle framework does on an upgrade). There's not Apple API's to do this, so the solution is spawn a process temporarily, have the app terminate itself, and the spawned process can sleep in a loop a few times, and when it wakes up, check the ppid -- if it's been reparented, it knows the App is terminated, then it can re-open it and terminate itself.
Like I said, fairly niche, but I was just literally implementing this the other day and relying on the fact that my spawned process needs to outlive it's parent and become an orphan, which is possible using the current Process api. I'm guessing that in the vast majority of cases, having the child process terminate when the parent does would be desirable though, so that should be the default, and I'm fine with that. I also realize even if this new api doesn't ship with the appropriate escape hatch, someone could always fall back to the old Process api, or some lower level C functions -- I just wanted to mention it, because I'd rather use a newer and nicer API if possible, (Process is weird and klunky), and I'm guessing there are other (non-daemon) use cases as well, fwiw.
4 Likes
Ooo! That's a good use case. I have never done such thing.
I think that proposal should mention this, because people may try to do this without knowing that this is not supported.
That said, technically this is supported by the proposal: you do Subprocess.run(…) then exit the parent. As far as I know this will orphanize the child without killing it. But I feel that this is more of a hack, than a legit use.
1 Like
IO - Chatty children
There are valid use-cases for just calling wait and not reading stdout / stderr (or writing to stdin, for that matter - the subprocess could be waiting on that, too). e.g. you have secondary tasks which aren't driving the process directly but nonetheless want to know when it finishes.
Still, as you point out the current API is hazardous because it's too easy to naively call wait from the primary task and just deadlock. It'd be nice if you had to be more explicit, e.g. if wait took a parameter asking what you want to do with stdout / stderr. Maybe:
func wait(ignoringFurtherOutput: Bool)
Now callers have to explicitly choose the behaviour, so it's more their own fault if they choose poorly (assuming the documentation is very clear about the ramifications of the two choices).
Tangentially, wait is pretty vague. Wait for what? I'd rather it be called waitForTermination or somesuch.
IO - Pipe buffer size
I concur that it would be wise to include a buffer size specification. I'm not sure it matters greatly whether the buffering is done by the kernel or in userspace, which might provide a fortunate degree of flexibility in the Subprocess implementation to account for platform differences (e.g. on Linux maybe use kernel buffering, on other platforms with no or fixed-size pipe buffers, buffer in userspace instead).
Back-pressure is great, but has to be applied wisely. Stuttering processes in a pipeline - because buffers are too small to hide context-switching delays and inconsistent processing speeds - is annoying yet easily avoided most of the time.
As-if-unbuffered pipes?
Tangentially, can Subprocess guarantee that pipes behave as if they're unbuffered from a flush / sync perspective? Because you cannot flush or sync a pipe on Apple platforms (ENOTSUP) even though I suspect they are technically buffered in the kernel. It's critical for Subprocess that anything I write to stdin is immediately available to the subprocess, and likewise anything it emits is immediately readable to me, otherwise deadlocks are inevitable.
I was surprised to find no specification of this pipe buffering behaviour anywhere, that I could find. I figured it'd at least be defined in POSIX, but if it is it's well hidden. ![]()
IO - Default values
.discard is a terrible default, especially for stderr, because it will cause many people (mostly but not exclusively beginners) to unwittingly miss that their subprocess error'd out. That'll manifest in a variety of unpleasant ways, like silently accepting corrupt data (if something still comes out on stdout, even thought the subprocess might have been screaming at you via stderr that it's wrong or incomplete), or deadlock (waiting forever for something to come out of stdout, when the subprocess has communicated the error via stderr and is now waiting for instructions).
.redirect is a better option but as you point out may still cause errors. Though the nature of those errors is substantially better - it'll either no be a problem (if the subprocess doesn't hit any buffer limits in the pipes) or at least stands a good chance of being caught during testing (as the abrupt halt of the program waiting for the subprocess to exit).
Possibly there should not be default arguments for these parameters. They are pivotal to the behaviour - and correct usage - of the Subprocess instance, so it might be wise to require the caller to specify their intentions.
Or, to similar effect, separate them out into distinct constructors / methods (though I expect that'd be unwieldy due to the combinatorial nature of these three parameters).
AsyncBytes - Optional output props
I'm not sure making these getters throwing is better than them being optional, practically-speaking. Either way you're either living dangerously (try! or implicit unwrapping !) or writing hopefully pointless boilerplate - which is simpler with optionals than exceptions (guard let stdout = … else { … } vs do { … } catch { … }).
What would of course be best is if the compiler (e.g. via the type system) could ensure you cannot reference these if the Subprocess was not set up in the appropriate manner. I'm not sure how practical that is, though - I assume it'd require some pretty clever and complicated generics magic?
Sidenote: I suppose you could just try the getters and let callers deal with the "this should never happen" situation, but that's mean - and also similar to how Process behaves in a lot of situations today, which is really annoying when the thrown errors are just obtuse things like "Permission denied" with no backtrace or indication of origin otherwise - debugging them is a real pain in the arse, and practically impossible if you can't attach with lldb and break on the actual point of throw.
AsyncBytes - Read buffer
I think part of the problem here is that while lots of stdlib / Foundation / similar types can initialise from Sequences, very few have initialisers taking AsyncSequences. So you can't just do let output = String(process.standardOutput). It'd be better to improve String et al as that'll solve not just this Subprocess case but many cases.
I think it's wise to have stdin / stdout / stderr be fundamentally async, without too much convenience for treating them otherwise. Too much code is either outright wrong or at least inefficient because it unnecessarily and/or naively treats communication buffers as synchronous.
That said, having the fundamental iterator return blocks of data ([UInt8] or equivalent) would be better. It can have abstractions atop it for iterating as individual characters instead (like the existing lines convenience), but it's more efficient to work with chunks at a time where possible - and most uses don't actually want individual characters anyway.
StandardInputWriter - Call finish?
I concur that it's not ideal that callers just have to remember to call finish. I wonder if something could be done using non-copyable types or somesuch, to have the compiler help the programmer along? Some way to ensure you can't just silently let stdin go out of scope, you have to either explicitly close it or stash it somewhere (to be closed later).
Signals - ESRCH
It depends what they can throw. Throwing is fine if the only reason they can throw is because the subprocess is no longer running. Knowing that, one can just write try? and ignore the result, where appropriate. It's a little beginner-hostile because it may not be apparent that you usually need to do that, especially for the most common case of just wanting to kill the subprocess. But you'll have to write some kind of try - the compiler will require it - so the worst case¹ is just someone writing an unnecessary exception handler.
Returning a boolean works too, of course - as long as it's @discardableResult - but it requires substantially more work to throw an error (define a custom error type, check the return value, throw as necessary).
Tangentially, if we had an ignoring keyword this would be fool-proof (by building on typed throws). e.g.:
try subprocess.signal(.SIGKILL) ignoring .alreadyTerminated
That way if signal ever starts throwing additional types of errors in future, they won't be silently ignored (and that eventuality is not a binary-incompatible change, unlike making a non-throwing method start throwing, or changing the return type from a simple Bool, etc).
Signals - Duplicate pid
I'm not sure what's formally guaranteed, but in practice PIDs are allocated sequentially and only reused if the counter wraps around (typically at 4 Mi or 100k, on Linux & Unix respectively, or ~4 Bi on Windows). Which is quite a lot of process launches in-between (especially on Windows). So I think the odds of tripping over this bug are slim.
But you're right that Subprocess really should disable signal-sending immediately once it detects the subprocess has exited (which should happen virtually immediately without any tickling of the Subprocess APIs). No need to entertain this bug, no matter how unlikely its occurrence might be.
IIRC some systems (e.g. Linux) don't have a distinction between process IDs and thread IDs, so every thread bumps this counter by one. Which may make it an order of magnitude (or two) more likely to wrap around. But still an infrequent occurrence in all but pathological systems.
Environment - init
That's not the same thing.
A .empty could be added as a convenience - I'm mildly in favour of it, for readability - but is equivalent to .custom([]). There's no way to require a non-empty dictionary
String vs Data
Tangentially, will the compiler happily accept .custom([]) even though it's ambiguous as to which of the static methods it refers to (since the type of [] could be inferred as either using String or Data)?
In any case, maybe it'd be better to have an e.g. EnvironmentVariableRepresentable protocol that StringProtocol and DataProtocol could be conformed to, and not overload for merely two specific cases (String and Data)? That'll also allow 3rd-party types to conform and thus be directly usable without manual type conversion.
The cost of existentials here will be insignificant (launching a process is waaaay more expensive than unboxing some existentials).
Ergonomic & documentation
I think the constructor problem you mention might be a tooling problem more than a code design problem. I agree that the overloads are not ideal - it's generally confusing to mix default arguments with overloads, and that's particularly true here for Subprocess since run has so many parameters. But otherwise, default arguments are great and it's the tools which make them difficult, because of their naive approach of just trying to show you every combinatorial possibility. The tools can in principle be improved, so I don't like the idea of compromising an otherwise fine design.
¹ Technically it's them naively using try!, but as with all uses of ! that's on them.
2 Likes
Sorry, I don't have time to respond to everything. But really quickly for this one. If we run this in the most current proof-of-concept:
try await Subprocess.run(
executing: .at(FilePath("\(bin)/cat")),
arguments: ["Pride and Prejudice.txt"] // bigger then pipe
) { p in
return 1
}
This will SIGPIPE the child, because after the body argument finishes running it will close the child stdout.
If we ignore this then we may end up in the following situation:
body(user supplied closure) finished running- we are in Foundation code
- child is still writing to
stdout
This can deadlock when the child fills the pipe, and now they wait for somebody to read, while we wait for them to finish. The question is: should the Foundation take it on itself to read the whole output and allow child to continue? There is no user facing API, we are solely in Foundation.
If redirect is the default then child will fill pipes. What if user does not read the pipe? Possible deadlock. Especially true if it is the default value. There are a lot of programs that print a lot.
This brings us again to: should the Foundation read the pipes if user forgets to? This may be the only way the child is able to finish.
Sorry, I may be a little bit on the edge about the "filling pipes" issue, but I had this exact problem in production. And I really started appreciating Popen.communitate in Python.
Putting this on the user could be okaish. Then in the closure they would call wait(<bool param>). Currently on the Subprocess we only have: pid, stdout, stderr and signals. So that would be another method.
1 Like
If we go non-optional with precondition then we can provide helpful message: Subprocess.stdout is available only if you select redirect. Explicitly unwrapped optional will just throw and user still does not know what they did wrong.
Just make this call idempotent - like I proposed in the long post. Then subprocess can call it again just to be extra sure. In the worst case it will do nothing, because the file is already closed. I assume that there is a point in time that the subprocess can make the decision that the input is no longer needed, like after the child process terminated.
This will make it optional for the users to call this method. They can, if this is their use-case.
I see that it can also throw:
EPERM The calling process does not have permission to send the signal to any of the target processes.
Technically also:
EINVAL An invalid signal was specified.
My idea would be:
- throw on EPERM, EINVAL
- default handling of ESRCH that converts it to
@discardableResult Bool
You do not have to define custom Error type. Swift system already has it: swift-system/Sources/System/Errno.swift at main · apple/swift-system · GitHub
You just do: throw Errno.noSuchProcess.
This would have similar semantic to: try subprocess.signal(.SIGKILL) ignoring .alreadyTerminated. Though discardable result makes it hard to discover for the users. And there is some boilerplate.
It all depends what is the most common usage pattern. What users expect to happen. Error? Or silent ignore with possible optional handling if they need to.
process.kill()
process.wait()
Should this trow if already terminated?
Damn, I was supposed to answer just the 1st part.
precondition should rarely be used in library code. If your library crashes my application, for anything less than true wild memory corruption, I will be very sad. As will the users of my apps.
Programmer errors are not an excuse to crash. Graceful failure is important, as is not magnifying problems (e.g. just because some background task messes up running some tangential subprocess doesn't mean my whole app should crash, throwing away all my users' work).
That said, your point stands somewhat for throwing exceptions vs returning nil. Either way you can get a nice error message, but it is arguably more convenient to get that "automatically" via the library's exception than have every caller have to emit it manually.
Optionals are cheaper than exceptions, though. So in part it depends on whether it's considered acceptable to "lazily" call these getters without trying to ensure the Subprocess was created in the right way. That might sound silly, but I could believe that with a bit of abstraction or generalisation that might actually make a lot of sense, for design or simply convenience purposes.
Anyway, despite the verbage here I don't feel strongly about optional vs throws in this case. I was just pointing out that both can be considered.
It's not about calling it multiple times, it's about ensuring it's called [at least] once.
Some cases don't care if it's called - maybe the subprocess in question doesn't wait on stdin and will exit regardless. But it doesn't hurt to close stdin in that case, and it's safer to err that way.
I recommend never doing that in a library. Or probably any code.
I say that based on decades of painful experience with exactly that pattern in Foundation and Apple's libraries more broadly.
It's incredibly frustrating to see things like this in the console:
Error Domain=NSPOSIXErrorDomain Code=1 "Operation not permitted" UserInfo={_NSURLErrorFailingURLSessionTaskErrorKey=LocalDataTask .<3>, _kCFStreamErrorDomainKey=1, _NSURLErrorRelatedURLSessionTaskErrorKey=( "LocalDataTask .<3>" ), _kCFStreamErrorCodeKey=1}
That's utterly useless in any non-trivial program. What wasn't permitted? Where? When? Why?
Unfortunately the Error protocol is so lacking in useful information (e.g. a backtrace, or even just a source function or file name) that you can't use errors that generic. You have to provide case-specific errors that can be intuitively attributed to their source (in real, complicated programs). Otherwise, you have to put exception handlers around every afflicted try expression in order to pin down errors [close] to their origins, which really undermines the major benefit of exceptions (the ability to separate sources of errors from error handlers) as opposed to e.g. Result.
Beyond that, you raise an excellent point that sending the signal can in fact fail for a variety of reasons. Those reasons do need to be conveyed, so throwing a suitable error is the best option.
I'm not sure about separating out ESRCH, though… even dismissing the possibility of library errors (e.g. somehow using the wrong PID), the meaning of ESRCH seems context-sensitive. e.g. if you were sending SIGTERM or SIGKILL then yeah, it's probably irrelevant; the process is gone, that's all that matters. But if you were sending any other signal, like SIGCONT, I doubt you want to ignore that.
Maybe the least bad option really is to just consistently throw exceptions, but try to be very clear and prominent in the documentation that callers should anticipate cases like ESRCH.