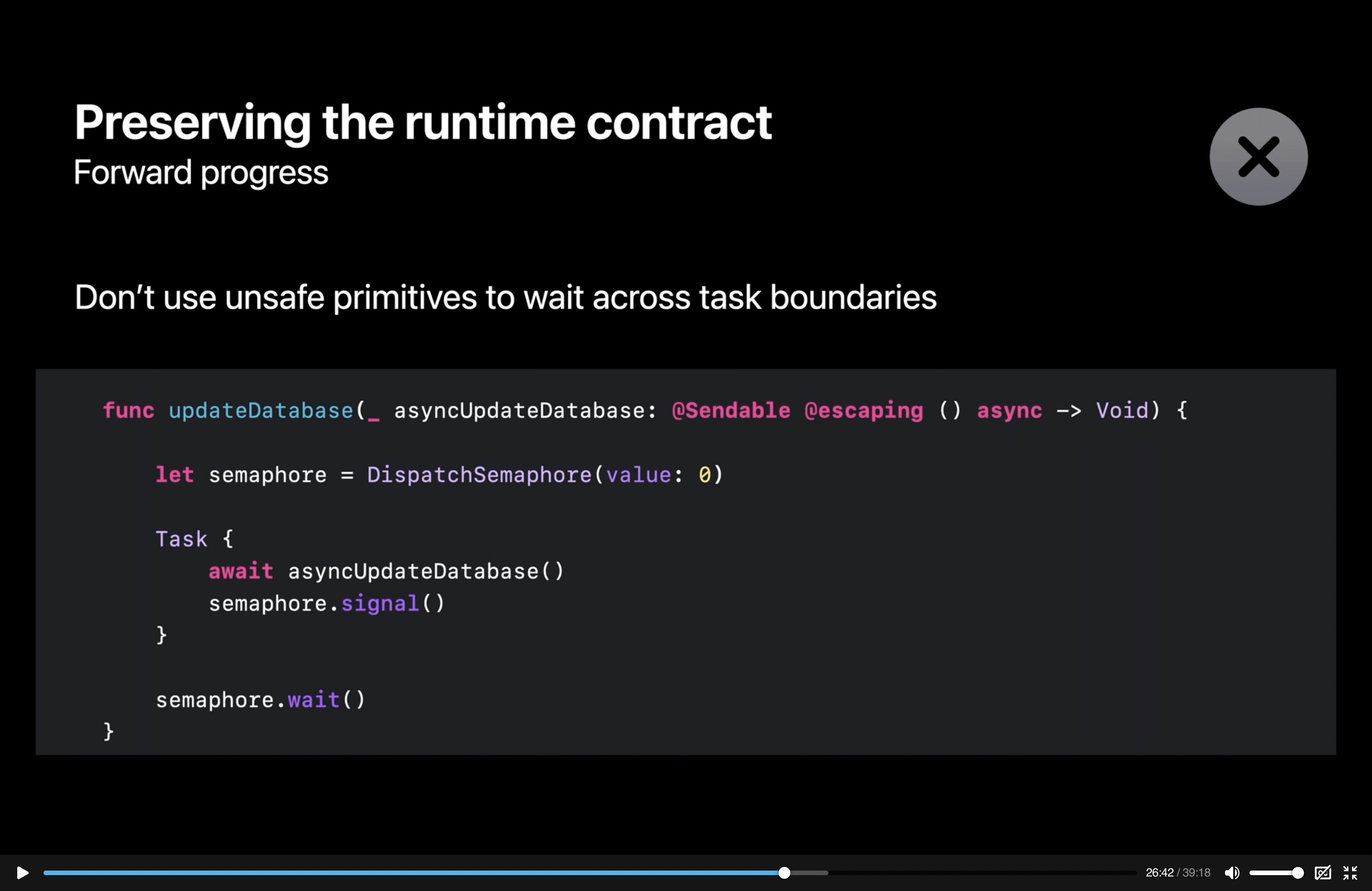
I'm migrating an existing project which uses both completion handlers and semaphores. I'd very much appreciate other's critique of the functions I've created to facilitate this migration.
I've created the inverse of withCheckedContinuation et al called withAsync and withThrowingAsync in both blocking and non-blocking forms. They're there to account for a number of transitions I need to make. Here's a few examples:
withThrowingAsync {
return "withThrowingAsync with completion handler"
} completion: { result in
print(result)
}
let value = try withThrowingAsync {
return "Blocking withThrowingAsync"
}
print(value)
let task = Task {
return "Waiting on a Task"
}
print(task.wait())
Completion handlers
Usage
withThrowingAsync {
// Do some awaiting then return the result or throw
} completion: { result in
// Handle the result of the async block in good old GGC/blocks
}
Implementation
public func withAsync<Object>(priority: TaskPriority? = nil, operation: @escaping @Sendable () async -> Object, completion: @escaping (Object) -> Void) {
Task(priority: priority) {
let object = await operation()
completion(object)
}
}
public func withThrowingAsync<Object>(priority: TaskPriority? = nil, operation: @escaping @Sendable () async throws -> Object, completion: @escaping (Result<Object, Error>) -> Void) {
Task(priority: priority) {
do {
completion(.success(try await operation()))
} catch let error {
completion(.failure(error))
}
}
}
Semaphores / blocking code
Usage
let value = try withThrowingAsync {
// Do some awaiting then return the result or throw
}
// wait just before here then handle the result of the async block in normal code
Implementation
public func withAsync<Object>(priority: TaskPriority? = nil, operation: @escaping @Sendable () async -> Object) -> Object {
let semaphore = ObjectSemaphore<Object>()
withAsync(priority: priority, operation: operation, completion: semaphore.signal)
return semaphore.wait()
}
public func withThrowingAsync<Object>(priority: TaskPriority? = nil, operation: @escaping @Sendable () async throws -> Object) throws -> Object {
let semaphore = ObjectSemaphore<Result<Object, Error>>()
withThrowingAsync(priority: priority, operation: operation, completion: semaphore.signal)
return try semaphore.wait().get()
}
ObjectSemaphore is a bit like Combine.PassthroughSubject but blocking. It encapsulates the common scenario of trying to safely handle the results of an async completion handler we are waiting on.
private class ObjectSemaphore<Object> {
let semaphore = DispatchSemaphore(value: 0)
private var _object: Object!
func signal(_ object: Object) {
_object = object
semaphore.signal()
}
func wait() -> Object {
semaphore.wait()
return _object
}
}
Blocking Tasks
For completness I've also added a few function to make waiting on Task object a bit easier, though I don't think they're needed on my project.
extension Task where Failure == Never {
func wait() -> Success {
return withAsync(priority: nil) {
return await value
}
}
}
extension Task where Failure: Error {
func wait() throws -> Success {
return try withThrowingAsync(priority: nil) {
return try await value
}
}
}