I recently opened a topic on the Apple Developer Forums titled FileManager.contentsEqual(atPath:andPath:) very slow, and an Apple Engineer suggested that I open a discussion "there" (hopefully this forum is the right place). So I'd like to open a discussion about possibly improving the default implementation of this method, and maybe even adding a new parameter that allows a custom buffer size to further improve its speed.
Looking at the source code, I see that it's using a buffer size of 8 * 1024, which is tiny.
Now consider the following implementation, which allows a custom buffer size:
extension FileManager {
func fastContentsEqual(atPath path1: String, andPath path2: String, bufferSize: Int, progress: (_ delta: Int) -> Bool) -> Bool {
do {
let sourceDescriptor = open(path1, O_RDONLY | O_NOFOLLOW, 0)
if sourceDescriptor < 0 {
throw NSError(domain: NSPOSIXErrorDomain, code: Int(errno))
}
defer {
close(sourceDescriptor)
}
let sourceFile = FileHandle(fileDescriptor: sourceDescriptor)
let destinationDescriptor = open(path2, O_RDONLY | O_NOFOLLOW, 0)
if destinationDescriptor < 0 {
throw NSError(domain: NSPOSIXErrorDomain, code: Int(errno))
}
defer {
close(destinationDescriptor)
}
let destinationFile = FileHandle(fileDescriptor: destinationDescriptor)
var equal = true
while autoreleasepool(invoking: {
let sourceData = sourceFile.readData(ofLength: bufferSize)
let destinationData = destinationFile.readData(ofLength: bufferSize)
equal = sourceData == destinationData
return sourceData.count > 0 && progress(sourceData.count) && equal
}) { }
return equal
} catch {
return contentsEqual(atPath: path1, andPath: path2) // use this as a fallback for unsupported files (like symbolic links)
}
}
}
This is how the two implementations compare with files of different sizes (with the same buffer size of 8_192):
| File size | FileManager (s) | Custom (s) | Speedup |
|---|---|---|---|
| 1'000 | 0.00016 | 0.00009 | 1.7x |
| 1'000'000 | 0.009 | 0.001 | 9x |
| 10'000'000 | 0.21 | 0.11 | 1.9x |
| 100'000'000 | 2.0 | 0.9 | 2.2x |
And here are the results of the custom implementation for different file and buffer sizes, each one repeated 5 times.
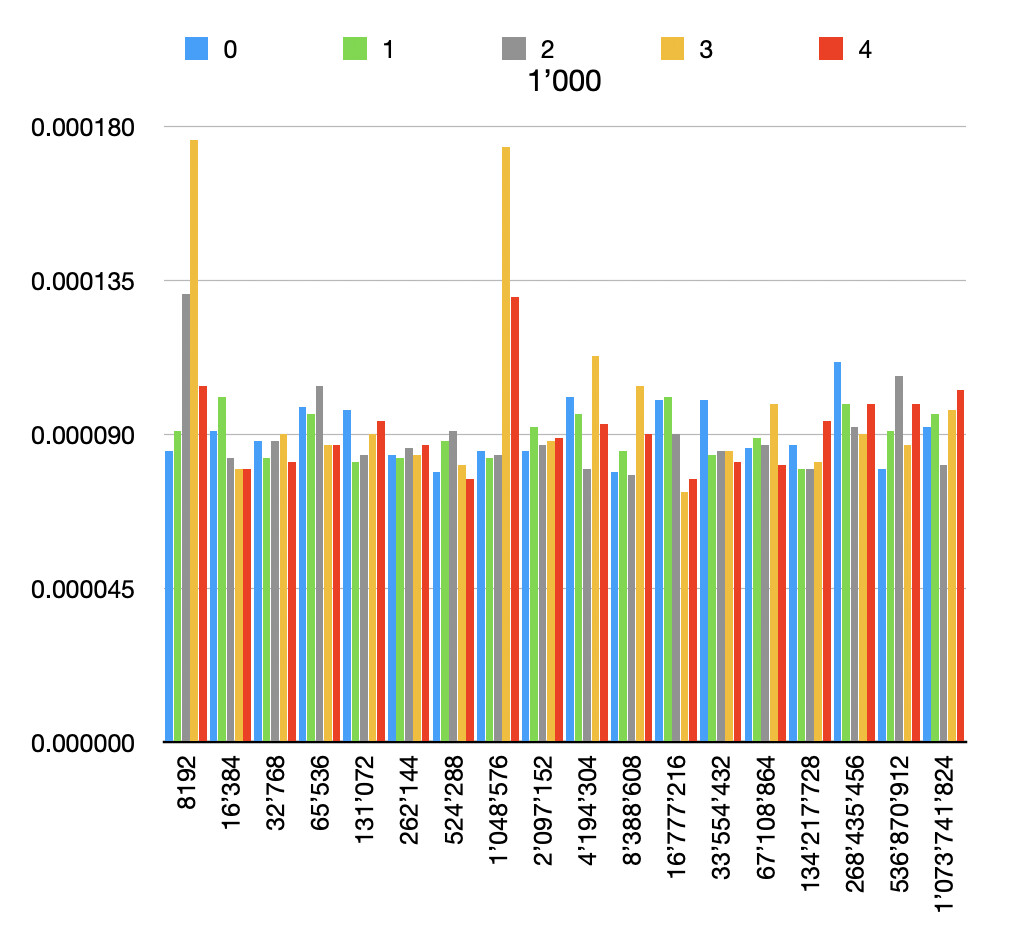
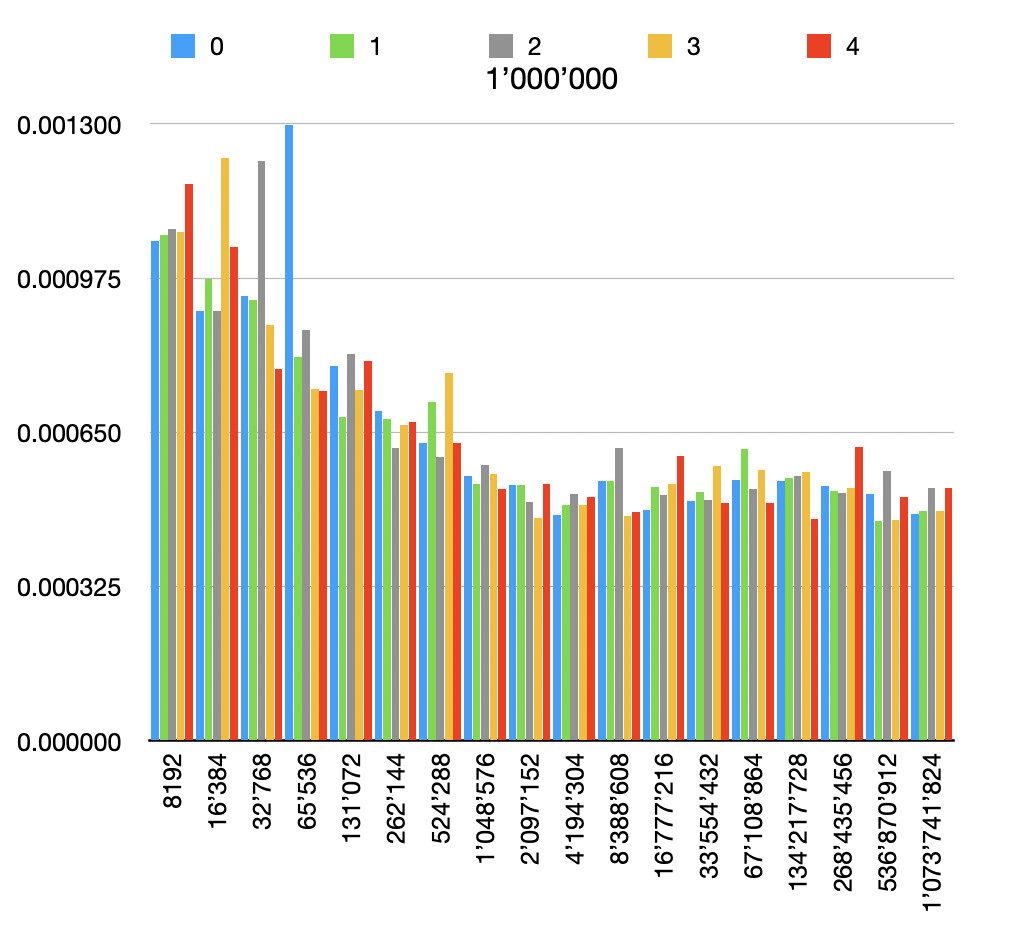
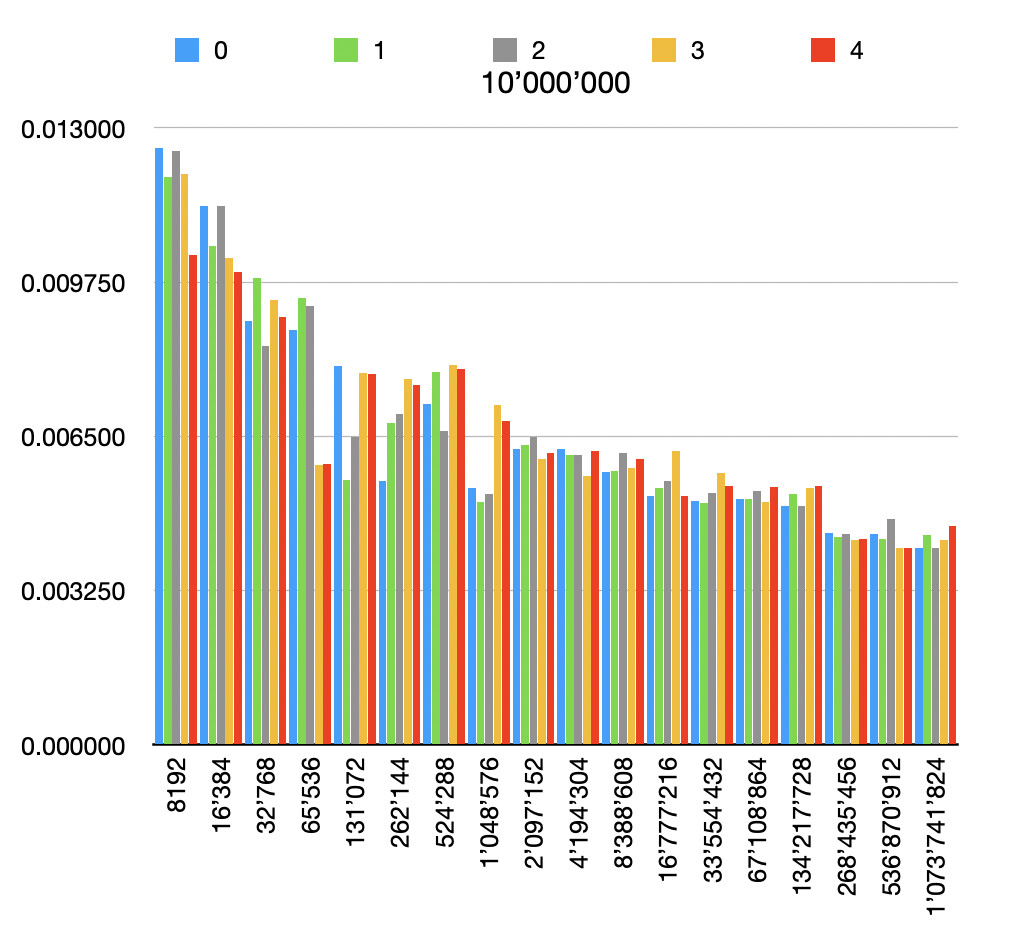
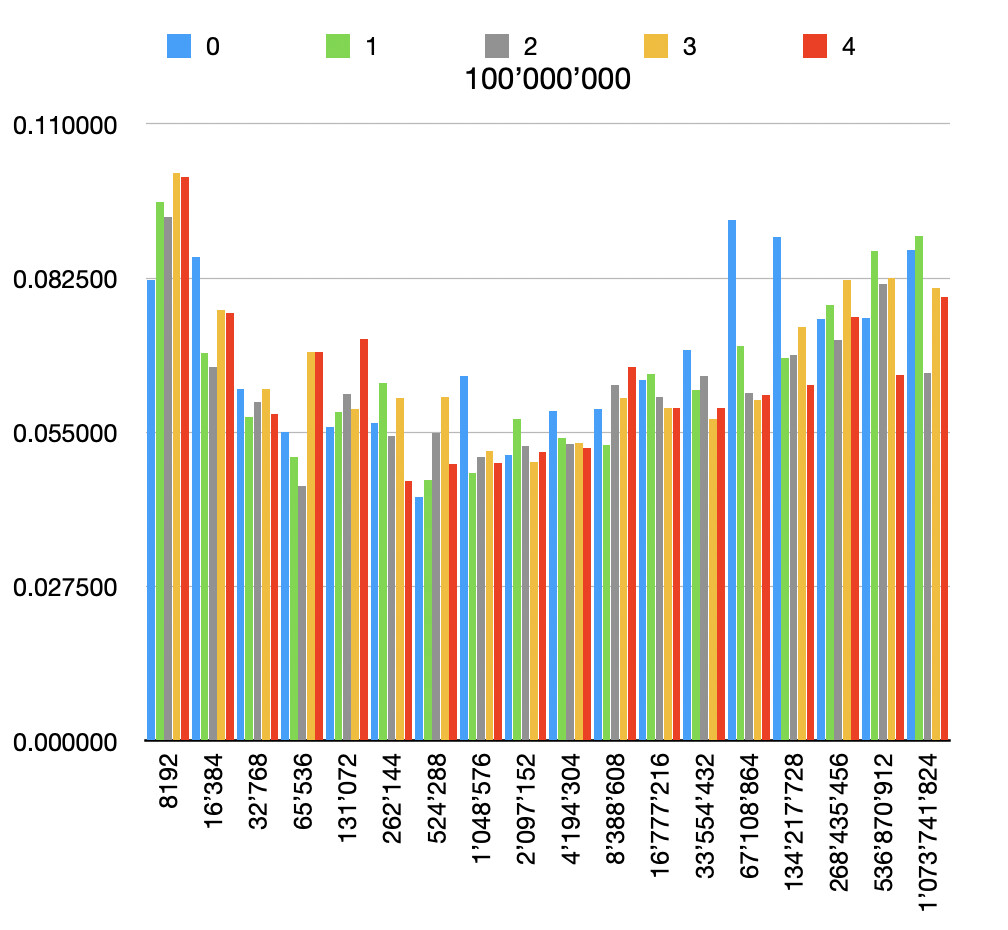
This is the code I used for testing. I then opened the generated .tsv files in Numbers on Mac to generate the graphs.
let url = FileManager.default.temporaryDirectory.appending(path: UUID().uuidString, directoryHint: .isDirectory)
try! FileManager.default.createDirectory(at: url, withIntermediateDirectories: true)
print(url.path())
let source = url.appendingPathComponent("file source")
let destination = url.appendingPathComponent("file destination")
print("page size", getpagesize())
let fileSizes = [1_000, 1_000_000, 10_000_000, 100_000_000, 1_000_000_000, 10_000_000_000, Int(getpagesize()) * 10_000]
let bufferSizes: [Int] = (10..<31).map({ 1 << $0 })
let repetitions = 5
var times = [[TimeInterval]](repeating: [TimeInterval](repeating: 0, count: repetitions), count: bufferSizes.count)
for fileSize in fileSizes {
print("fileSize", fileSize)
for (i, bufferSize) in bufferSizes.enumerated() {
print("bufferSize", bufferSize)
for j in 0..<repetitions {
try? FileManager.default.removeItem(at: destination)
createFile(source: source, size: fileSize)
createFile(source: destination, size: fileSize)
let date = Date()
let result = FileManager.default.fastContentsEqual(atPath: source.path, andPath: destination.path, bufferSize: bufferSize) { _ in true }
let time = -date.timeIntervalSinceNow
times[i][j] = time
}
}
let header = ([""] + bufferSizes.map({ NumberFormatter.localizedString(from: $0 as NSNumber, number: .decimal) })).joined(separator: "\t")
try! Data(([header] + (0..<repetitions).map { j in
(["\(j)"] + (0..<bufferSizes.count).map { i in
return timeToString(times[i][j])
}).joined(separator: "\t")
}).joined(separator: "\n").utf8).write(to: url.appendingPathComponent("\(fileSize).tsv"))
}
func timeToString(_ time: TimeInterval) -> String {
return String(format: "%.6f", time)
}
func createFile(source: URL, size: Int) {
let buffer = UnsafeMutableRawBufferPointer.allocate(byteCount: size, alignment: Int(getpagesize()))
buffer.initializeMemory(as: Int.self, repeating: 0)
let fp = fopen(source.path, "w")
let success = fcntl(fileno(fp), F_NOCACHE, 1)
assert(success == 0)
let bytes = fwrite(buffer.baseAddress!, 1, size, fp)
assert(bytes == size)
fclose(fp)
}