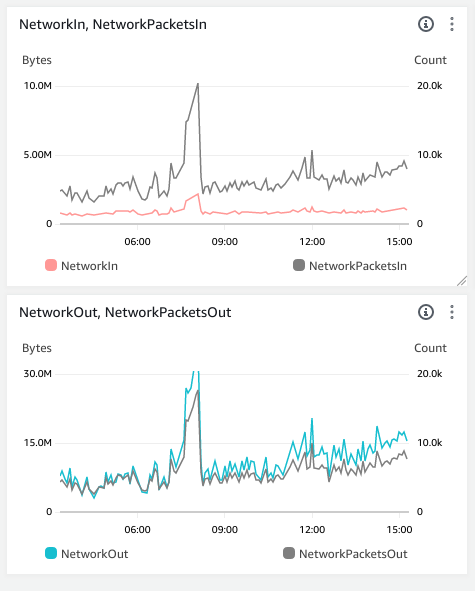
swiftinit survived this one, but three hours later, it inexplicably crashed and the only log records i have are:
Nov 04 17:09:55 ip-172-31-90-47.ec2.internal launch-server[537707]:
error: NIOAsyncWriterError.alreadyFinished
Nov 04 17:09:55 ip-172-31-90-47.ec2.internal launch-server[537705]:
/home/ec2-user/bin/launch-server: line 7: 537707 Illegal instruction /home/ec2-user/bin/UnidocServer --mongo localhos>
Nov 04 17:09:55 ip-172-31-90-47.ec2.internal systemd[1]: org.swiftinit.main.service:
Main process exited, code=exited, status=132/n/a
Nov 04 17:09:55 ip-172-31-90-47.ec2.internal systemd[1]: org.swiftinit.main.service:
Failed with result 'exit-code'.
Nov 04 17:09:55 ip-172-31-90-47.ec2.internal systemd[1]: org.swiftinit.main.service:
Consumed 8min 55.304s CPU time.
Illegal instruction of course, could mean literally anything for a swift application. any tips for how to begin investigating this?
Often, Illegal instruction means you're executing junk data from a random memory location. If so, it's a logic error and should be reproducible in a debug build with tighter preconditions around unsafe pointers, or in an ASan build.
Capturing a backtrace may also help.
I'm not sure that it is directly caused by the DDOS attempt. The 3 hour gap would also suggest that they may be unrelated.
Which Swift version is this? Swift 5.9 should automatically give you backtraces on Linux. Before Swift 5.9 you'd need to include the swift-backtrace library.
And as you probably know already, 'illegal instruction' is what Swift uses for all its preconditions. So integer overflow, array out of bounds, precondition(...) calls, ! on nil, ... So yeah, without at least the knowledge where it exploded there's not much you can do to debug.
I'd say log extensively. Perhaps use a very compact form of logging to fit as much as possible but log literally everything, ultimately every function call with parameters and return values. Maybe you will not be able doing so with the logging infrastructure you are using now, in which case you'd have to invest into your own custom logging infrastructure. You can log to a memory ring buffer (say, 1GB) so long as you manage to write that memory down to a file upon crash. Once you captured a very detailed log leading to the crash you'd be able tracking down the issue after some detective work. The crash in question is probably related to "NIOAsyncWriterError.alreadyFinished" just before it, but if you log extensively you'll probably see not just that line but some 100s relevant log statements just before that that will shed the light why exactly that'd happened.
yeah, this is what i found strange because i did not do anything yet to try and suppress the default 5.9 behavior which should print the backtrace.
my first suspicion is this might be the same buffering problem i’ve had before with print and journalctl. i need to look into this more.
it smells to me like a query-of-death situation. i don’t know how to reproduce this locally, because it likely only happens on a single page that exists in the production database. the first step is to get the backtrace to flush to disk before the process exits.
Hmm okay, that is of course possible. Let's CC @al45tair to get insights on how exactly it's printed. Is it really going through stdio (which would be suspect to buffering) or directly through write(STDERR_FILENO, ...) which wouldn't (of course the other end could still 'forget' to read it from the pipe). If it did go through stdio I'd assume it does an fflush(stderr) in the backtrace lib but let's hear from Alastair.
One thing that you could try to debug this issue is to deliberately crash your program by introducing a /crash_me_please_1234 route (choose a hard-to-guess URL slug). That route would just have precondition(false, "nope"). Then you can hit that endpoint in an environment that replicates production near perfectly (same supervisor processes etc) and you could see if that reliably produces a backtrace as expected or if it doesn't.
If you can't get a backtrace out then I'd strongly suggest to debug that problem first. If you can't get the diagnostics you need, you'll have a bad time.
ha, swifties think alike, this was exactly what i was planning on doing. (and a general purpose “restart the server” would be useful for a lot of other things too)
it makes sense that something like an optional unwrap or an index out-of-bounds, which does not print any message of its own in release mode, would log nothing at all to journalctl.
Hmm okay, that is of course possible. Let's CC @al45tair to get insights on how exactly it's printed. Is it really going through stdio (which would be suspect to buffering) or directly through write(STDERR_FILENO, ...) which wouldn't (of course the other end could still 'forget' to read it from the pipe). If it did go through stdio I'd assume it does an fflush(stderr) in the backtrace lib but let's hear from Alastair.
The swift-backtrace program does use print(), which indeed goes via stdio and is subject to the usual C stdio behaviour (so, stderr is line buffered by default, while stdout's buffering depends on whether or not the program is attached to a pty).
However, swift-backtrace should be terminating normally (even if your program is crashing), which will flush the stdio buffers. There is certainly an issue with Swift programs using fatalError() to terminate, which doesn't flush stdio (contrast this, by the way, with C's abort(), which does — at least according to POSIX, though ISO created some confusion by suggesting abort() should be async-signal-safe, which makes flushing difficult).
now i try running the same application as a daemon, and visit the same endpoint.
in journalctl, it shows the first line printed by the fatalError call, but no backtrace!
One thing that is worth commenting on here is that the Swift crash reporter will usually log its output to stderrunless it's in interactive mode (which, by default, will happen if both stdin and stdout are attached to a terminal device).
I'd check the settings of StandardOutput, StandardError for your unit (and maybe their defaults, DefaultStandardOutput and DefaultStandardError) and also make sure that you aren't doing any of your own redirects.
If the problem turns out to be the logic in the Swift runtime choosing the wrong destination for the output, you can control it explicitly by setting SWIFT_BACKTRACE=output-to=stdout or output-to=stderr as necessary.
Ah, that'll be a pipe in almost all real-world server scenarios. And with pipes, stdio will operate in fully buffered mode. @al45tair but the print will happen in the swift backtracer sub-process, right? So even a fatalError() in the actual Swift program shouldn't cause issues.
But regardless, @al45tair can we fflush the right FILE * (stdout/stderr depending on the mode) after it has written the whole backtrace then? I don't think we should rely on something else flushing it, this information is too precious to take chances.
@al45tair but the print will happen in the swift backtracer sub-process, right? So even a fatalError() in the actual Swift program shouldn't cause issues.
Indeed. The fatalError() in the Swift program will only fail to flush output from the Swift program, not from the backtracer.
But regardless, @al45tair can we fflush the right FILE * (stdout /stderr depending on the mode) after it has written the whole backtrace then? I don't think we should rely on something else flushing it, this information is too precious to take chances.
If exiting the program doesn't fflush then that's a bug and we should fix that. We should be able to rely on that behaviour.
Okay, that sounds like it should work. I also assume that the actual (crashing) Swift program will wait for the backtracer to finish its work? Because if the Swift program exits before the backtracer can write its output, then the container will likely be already torn down by the time we write the backtrace.
If you happen to have built the executable with debug info, and you know the address of the illegal instruction the program ended on, then each illegal instruction arising from an overflow check or runtime trap should appear in the debug info as a single-instruction inlined function, whose name describes the reason for that particular trap. I'm not sure if the runtime backtrace accounts for inline frames, but looking up the address in a debugger might tell what kind of failure induced the trap.
Yes, but that's the bit we don't have. The address of the illegal instruction will print when the new backtracer has done its work. So if the container gets killed before that or the backtracer's output is redirected to another file then you won't see it.
I just chatted to @al45tair and I think we should add a single line
💣 Your program has crashed. A backtrace is being prepared, please wait a few seconds... (signal 5; instruction pointer: 0xdeadbeef)
inline in the signal handler right as we receive the signal. Then we get a two advantages:
the user knows they potentially need to wait a little
if the backtracer crashes or the pod has been killed prematurely (failing heartbeat), then at the fery least we have the signal and the instruction pointer
In non-interactive contexts, would it be too noisy to have the backtracer run without trying to do symbolication at all first, just giving the full raw backtrace with only addresses, and then do the work to generate the pretty human-readable backtrace?
Similarly, I know it’s hard to handle signals in a signal handler, but allowing the signal handler itself to be interrupted and cancelled during the backtrack collection process would also probably help the situation.
In non-interactive contexts, would it be too noisy to have the backtracer run without trying to do symbolication at all first, just giving the full raw backtrace with only addresses, and then do the work to generate the pretty human-readable backtrace?
We can't really do that, sadly. On Linux, at least, we need the symbols so that we can tell whether or not we're in an async frame.
Or, put another way, we could do that, but we'd then give a totally different backtrace the second time around. We already know this is confusing, because fatalError() already does something like this in some cases and people complain that it's failing to look up symbols.