Our C implementation was generally between 1.5× and 4.5× faster than a non-batched shuffle, depending on the array length and choice of RNG.
Now I’d like to contribute a batched shuffle implementation to the Swift standard library, if that’s something the project would want.
As I’m writing the code, there are a number of design decisions to make that I’d like to get other people’s input on. So I’m wondering where such discussions should take place. Here on this forum, or in a Github issue, or someplace else?
If there’s no change to API or behavior, then the best thing would be to open a PR that people can review and give advice on.
If there’s a behavioral change when used with a seeded RNG, we should talk a bit about how we might mitigate that for any users who need to maintain the current behavior because they are doing things like reproducible simulation or procedural generation.
This is not production-ready, but it gets the idea across. There’s the main shuffle method shuffle64, as well as a helper method that handles one batch at a time _partialShuffle64.
The core operation is full-width multiplication of 64-bit values, which is fine for 64-bit systems but I imagine that on some 32-bit systems that might not be particularly fast.
I can draft a 32-bit implementation as well if that would be helpful. It would be mostly similar, just with smaller batches. Though for maximal efficiency it would probably call generator.next() to produce 64 random bits, then split them into a pair of 32-bit words. That way each RNG call would actually cover two (smaller) batches.
Each of the following produced a significant speedup:
Using assert instead of precondition (I believe they will all be _internalInvariant since they are checking for mistakes in the implementation, and user code can never hit them)
Scratch space is now InlineArray instead of Array
Scratch space is the correct size for each batch (except possibly the final batch)
Unfortunately, that last change also means there is now a pyramid of doom that I don’t know how to get rid of.
The part which had been open-coded with a comment saying it could be a loop instead, now cannot be a loop because integer generic parameters must be compile-time constants and cannot depend on a loop iteration variable.
I also tried having the helper method declare its own scratch-space, but that was noticeably slower than taking it as an inout parameter.
In both cases the batched shuffle is significantly faster than the unbatched shuffle.
I’m actually kind of surprised that the speedup is so large with PCG, and it’s making me question whether I wrote the benchmarks correctly. At least with SystemRNG the graph shows inflections where the batch size changes at 512, 2k, 16k, and 512k, so that’s reassuring.
All right I ran the benchmarks with Xoshiro256++ and as you say it’s a little faster than PCG, though the batched version is about the same so the speedup is slightly smaller.
I also tried a custom RNG that uses arc4random_buf to generate randomness in blocks of 2KB, thus amortizing the overhead of the system call, and vends it out as 256 UInt64 values. The results for small sizes are meaningless, but at large sizes the performance is more in line with what I expect for a fast generator. Batching still has a significant benefit, but not as large as I’m seeing with PCG and Xoshiro.
Basically, I’d expect a blue curve like in the ArcBuf 256 graph for all the fast generators, and I’m not sure why PCG and Xoshiro have a noticeably larger speedup than that.
If someone else is able to benchmark this batched shuffle implementation I’d love to see if they get similar results.
IIUC PCG is an LCG with an extra whitening step at the end, so I imagine it just has a lot of linear data dependencies. Xoshiro is less linear and computes its result before permuting its state, so it should have less dependencies. I know there's a SIMD version of Xoshiro256+, but I think that needed to be hand-rolled. Does compiling with -Xcc -march=x86-64-v3 help?
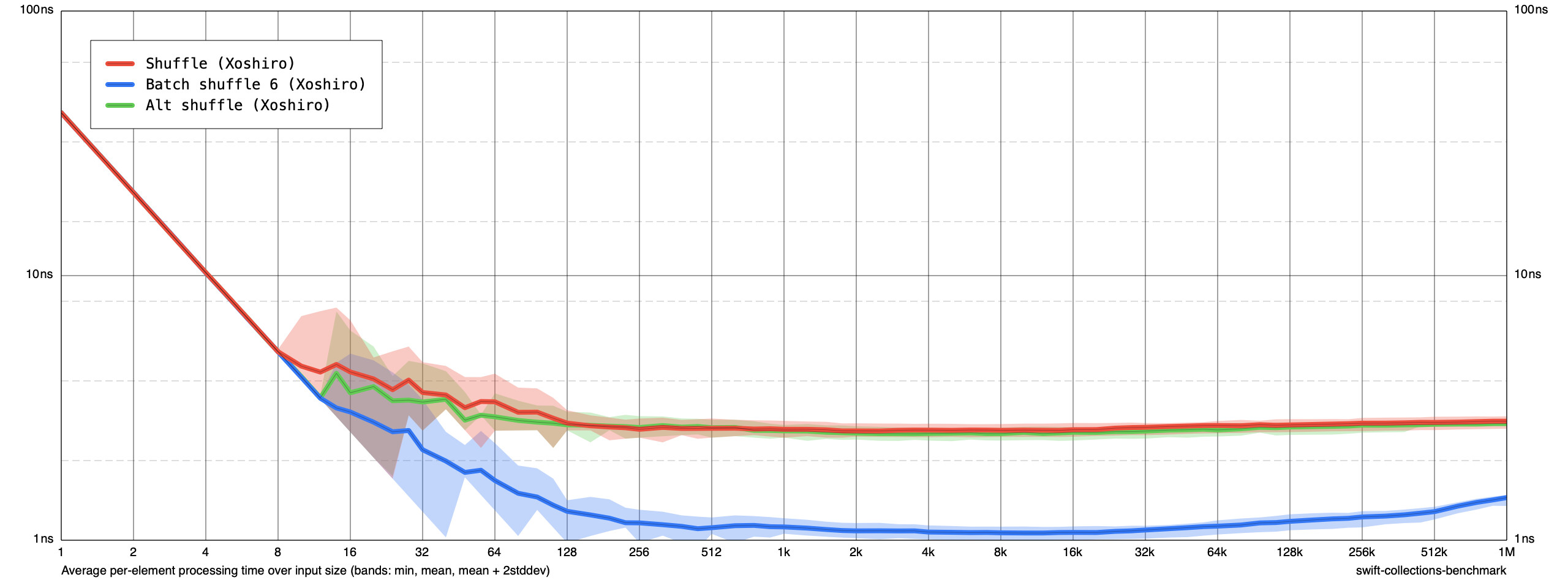
Now for PCG the speedup from the green curve (batching only the swaps) to the blue curve (using batched dice rolls) is right in line with what I’d expect. Of course it’s not a perfect comparison, maybe I should’ve had the green curve use the same batch sizes as the blue curve instead of always using 6, but it tells us something at least.
This makes me much more confident in these benchmark results now. The speedup from the dice rolling is right where I expect, and there seems to be some additional benefit just from batching the swaps, at least for the PCG generator.
My next decision point is whether to cap the batch size at 6, or to go up to 8 for small counts. Input is welcome.
I ran benchmarks with both (switching to 8 at n = 64, though n = 100 might be better), and it made a small difference with the system RNG, but no difference at all with the fast RNGs.
I also took the benchmarks out to n = 4M to see what happens when the array doesn’t fit in my CPU cache (16MB can hold 2M 64-bit ints), and I used a slightly different benchmark configuration to get cleaner results:
Notably, the jagged lines at small sizes in the first graph are not noise, but in fact indicate when the number of batches required for the shuffle goes up. For example, 7 items can be shuffled with 1 batch of 6, but 8 items cannot, so the blue curve jumps up at n = 8.
• • •
Also, if anyone has the ability to benchmark this on a 32-bit system, that would be much appreciated since I cannot.
Another decision point: should I switch from trapping operations to faster wrapping operations?
This mostly means changing UInt64(n - i) to UInt64(truncatingIfNeeded: n &- i) in three places. Also one case of Int(dice[i]) to Int(truncatingIfNeeded: dice[i]) and one case of n -= 1 to n &-= 1.
We know statically from the choice of batch sizes that there will never be an overflow, so both versions behave identically.
Here is the current code (I made some minor changes since the last linked version, for a tiny improvement on my machine): 64-bit batched shuffle · GitHub
The benchmarks show a small but measurable speedup from using wrapping operations with the fast RNGs, and no change with the system RNG. Note that the vertical scale on the graphs has changed, since the green curves now drop below 1ns per element:
Using PCG, the wrapping version is up to 25% faster than the trapping version. At n = 16k that makes it 4.2x instead of 3.4x faster than the unbatched shuffle.
Using Xoshiro, the wrapping version is up to 15% faster than the trapping version. At n = 16k that makes it 3.0x instead of 2.6x faster than the unbatched shuffle.
Also, according to swift.godbolt.org, the wrapping version compiles to 396 lines of assembly at -O optimization, while the trapping version compiles to 473 lines, about 20% more.
(Interestingly, if I change the compiler version from Swift 6.3 to Swift 6.2, those numbers drop to 350 and 416 lines, which is still about a 20% difference but it’s interesting that the older compiler gives shorter code.)
The optimizer proving that overflow is impossible is inherently fragile. I would go ahead and use the wrapping version. Especially since you've already measured such significant performance gains when using fast RNGs.