The latest commit in https://github.com/hibernat/concurrency-with-data-bug includes the DispatchQueue.concurrentPerform alternative code.
I did some rough time measurements, how many compressions or decompressions can my M3 Max (14 cores) do in 1 minute:
- DispatchQueue compressions: 750
- DispatchQueue decompressions: 1500
- Swift concurrency compressions: 800
- Swift concurrency decompressions: 270
All Xcode debug.
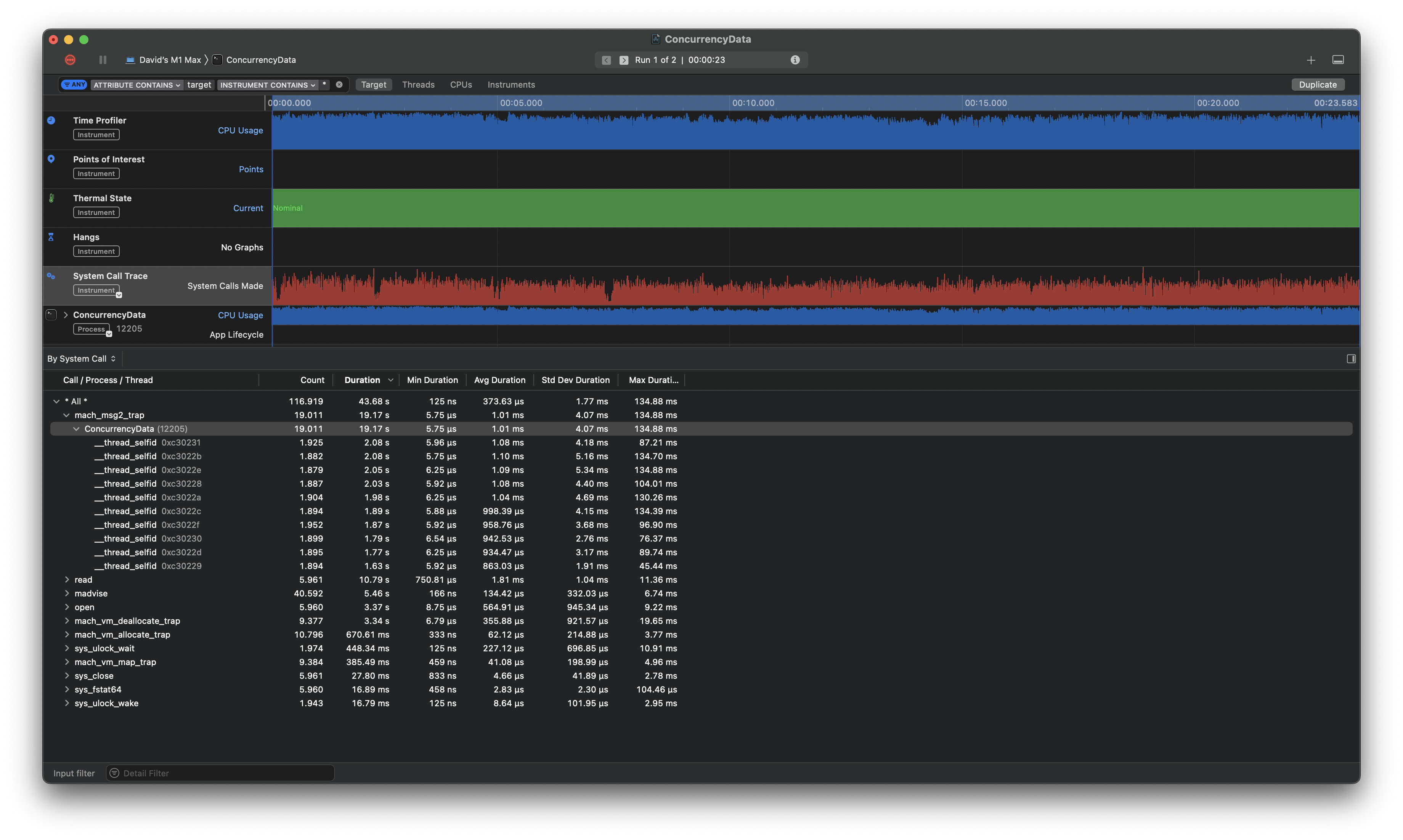
And here is visible the major performance issue: Swift concurrency decompressions are heavily affected by mach_msg2_trap, and not all CPU cores are performing. The Instruments screenshots above miss the important CPU chart, ideally with per core chart.
Until you hear fans, it is not performing well... 
The demo code in the repo gets performance degraded quickly, in a minute is the system so slow, that you literally wait for any new finished task in Swift concurrency.
I discovered the issue in my other code, where it runs 3-10 minutes till is becomes sluggish.
I run again the test with Swift concurrency decompressions, and it was able to finish 800 tasks in the first minute (seems OK), but then only 200 in the second minute.
Yesterday, when I experimented with the demo code, I put a long text in the Swift code, and converted it to Data. Then, I first compressed the data, and then decompressed again. This works fine.
Also, with the code in the repository, when I compress the file first (yes, compressed data compressing again), and then decompress, then it works fine. And, the performance is almost identical as just compressions: approx. 800 tasks finished in a minute.