Hi,
We're happy to announce that Benchmark now has shipped with what we believe is an API stable interface (which follows semantic versioning) with significantly improved capabilities compared to the initial release last fall (several thanks to the new underpinning Histogram foundation) .
Shiny new documentation is available outlining both setup and how to write benchmarks, largely thanks to @Joseph_Heck and the DocC team (and SPI for hosting!).
There are also some sample code on GitHub.
For those who have existing benchmarks there are a few (mostly search-and-replace) changes to the API between 0.9.0 and 1.2.0 which is the latest release - please see the release notes for migration notes (or check the changes to the sample code project above).
Thanks to the use of a built tool plugin, the boilerplate needed is now trivial:
import Benchmark
let benchmarks = {
Benchmark("MyBenchmark") { benchmark in
// Something to measure here
}
Benchmark("MyOtherBenchmark") { benchmark in
// Something to measure here
}
}
New is also the ability to run benchmark on a platform that does not have jemalloc available by setting up an environment variable that disables the jemalloc requirement:
> BENCHMARK_DISABLE_JEMALLOC=true swift package benchmark
Each benchmark is now run completely isolated so resident memory statistics etc should be consistent across runs now.
It's also possible to use --filter, --skip, --target and --skip-target with Regex to choose what benchmarks should be run.
Multiple output formats is now supported, including raw percentile data as well as data suitable for visualisation with online tools such as JMH and HDR Histogram plots or even piping output to e.g. Youplot.


There's also the support for grouping per metric or delta comparisons:
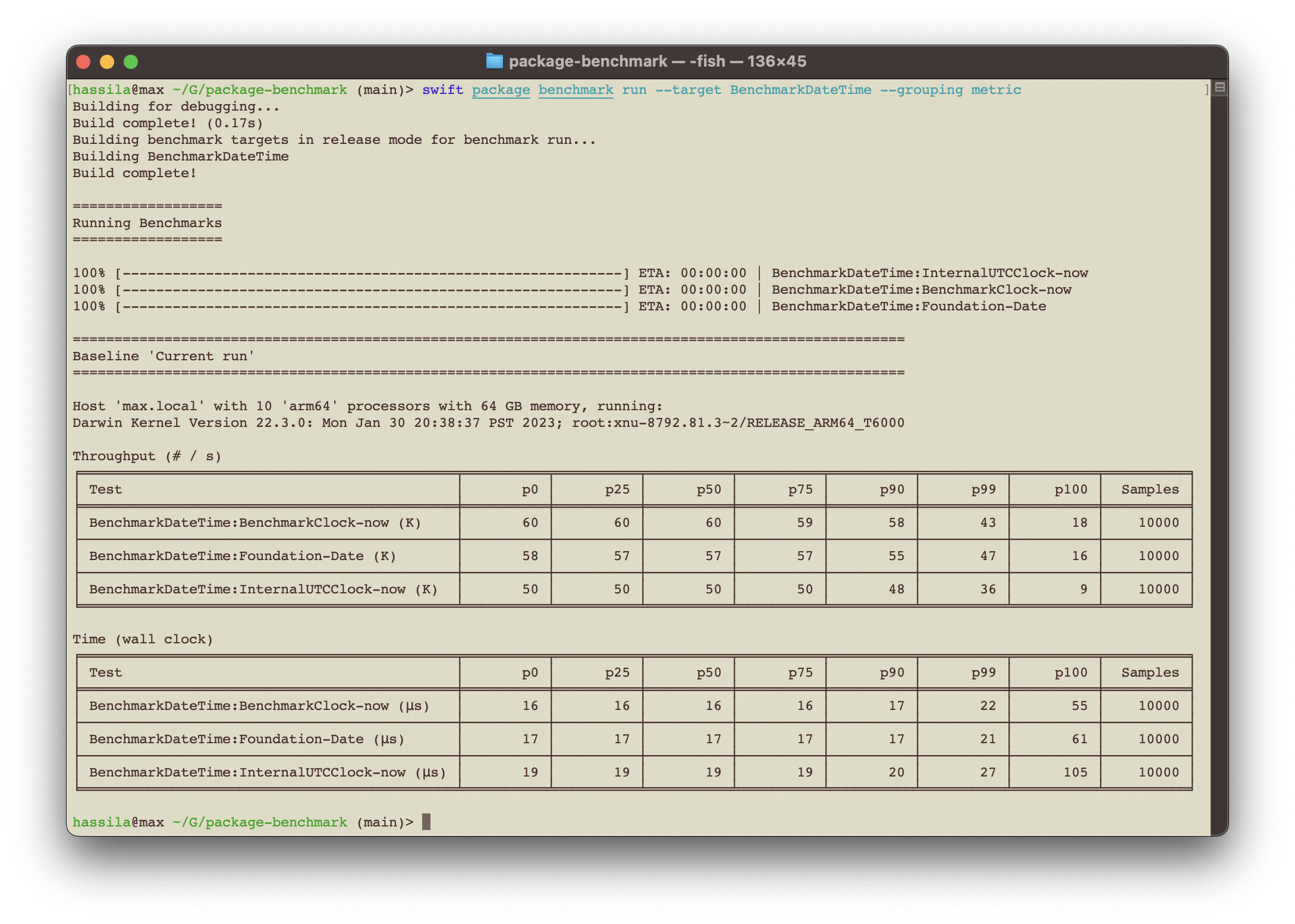

Also, there is extensive support for automation of benchmarks through CI, where either two branches (e.g.
main and PR) can be compared with custom deviation thresholds configured (absolute and/or relative) per metric supported by Benchmark.

Additionally, it's now also possible to check benchmarks results against an absolute set of values (useful if the number of permutations of toolchain/OS/repo is big, to reduce the build matrix) - although for most projects automated checks of PR vs main would be recommended.
Many thanks to the people who've provided feedback and please file issues / PR:s (or DM me here if you want offline feedback).
Cheers,
Joakim