At the risk of beating a dead horse, while I modeled my code snippets above on the original example, generally I would ensure I present the results in the order of the original array, not in a random order. I’d also make this “build the results collection with using task group with constrained concurrency” a generic function.
E.g., maybe, if one wanted an array of results with constrained concurrency, we’d make sure to order those results:
@inlinable public func arrayWithTaskGroup<ChildTaskInput, ChildTaskResult>(
of childTaskResultType: ChildTaskResult.Type = ChildTaskResult.self,
isolation: isolated (any Actor)? = #isolation,
from array: [ChildTaskInput],
maxConcurrent: Int,
operation: sending @escaping @isolated(any) (ChildTaskInput) async -> ChildTaskResult
) async -> [ChildTaskResult] where ChildTaskResult : Sendable {
await withTaskGroup(of: (Int, ChildTaskResult).self) { group in
precondition(maxConcurrent > 0)
var results: [Int: ChildTaskResult] = [:]
for (index, input) in array.enumerated() {
if index >= maxConcurrent, let result = await group.next() {
results[result.0] = result.1
}
group.addTask { await (index, operation(input)) }
}
for await (index, result) in group {
results[index] = result
}
return (0..<array.count)
.reduce(into: []) { $0.append(results[$1]) }
.compactMap { $0 }
}
}
Then my chopping routine is simplified, and the ugly “constrain concurrency” logic is abstracted out:
func chopIngredients(_ ingredients: [any Ingredient]) async -> [(any ChoppedIngredient)?] {
await arrayWithTaskGroup(from: ingredients, maxConcurrent: 3) { ingredient in
await chop(ingredient)
}
}
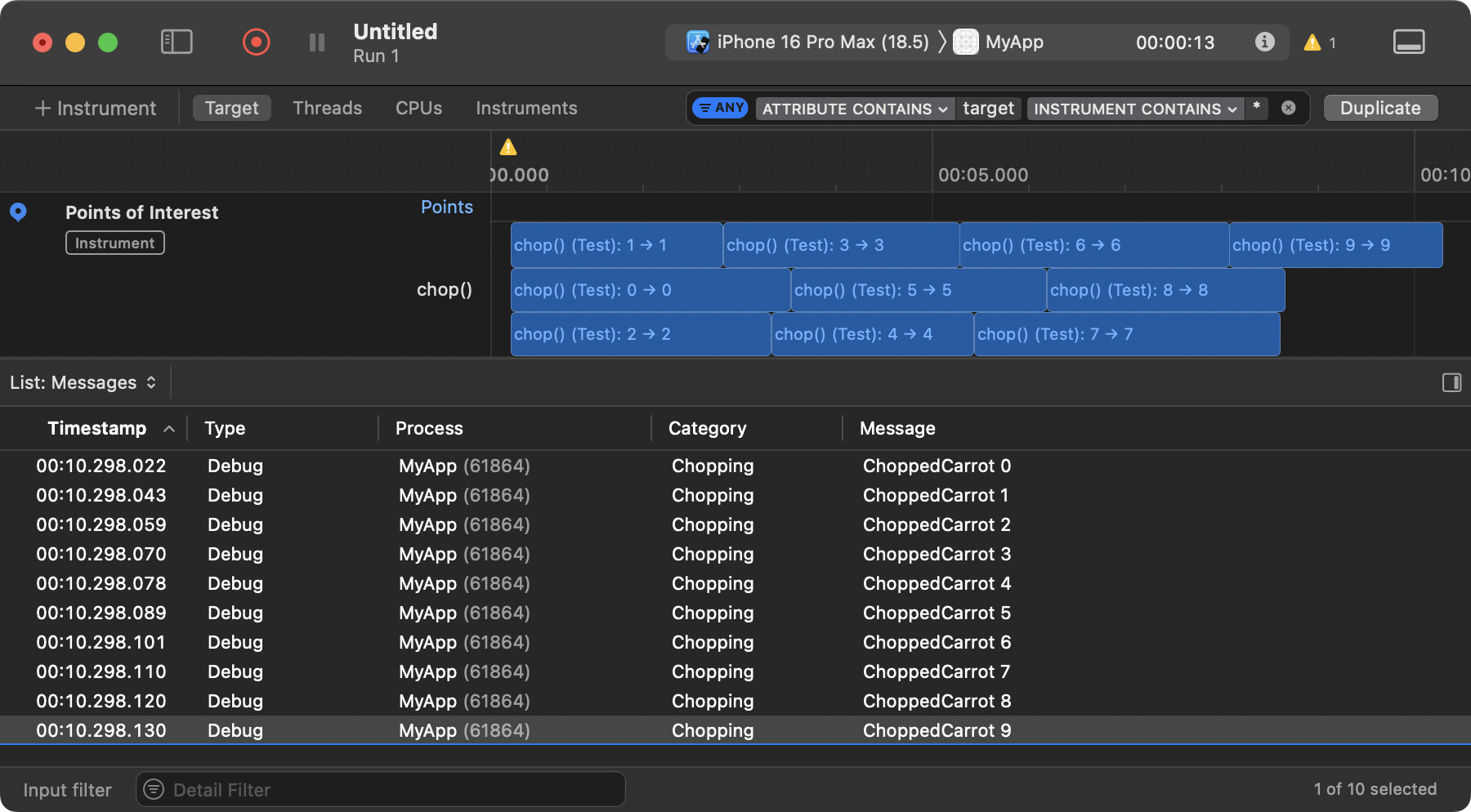
So, despite the tasks (constrained to a max of 3 at a time) finishing in a somewhat random order, the final results are in the order of the original array:
Or, I might return an order-independent structure. E.g., if the input was Identifiable, I might return a dictionary keyed by ID of the input:
@inlinable public func dictionaryWithTaskGroup<ChildTaskInput, ChildTaskResult>(
of childTaskResultType: ChildTaskResult.Type = ChildTaskResult.self,
isolation: isolated (any Actor)? = #isolation,
from array: [ChildTaskInput],
maxConcurrent: Int,
operation: sending @escaping @isolated(any) (ChildTaskInput) async -> ChildTaskResult
) async -> [ChildTaskInput.ID: ChildTaskResult] where ChildTaskInput: Identifiable, ChildTaskResult: Sendable {
await withTaskGroup(of: (ChildTaskInput.ID, ChildTaskResult).self) { group in
precondition(maxConcurrent > 0)
var results: [ChildTaskInput.ID: ChildTaskResult] = [:]
for (index, input) in array.enumerated() {
if index >= maxConcurrent, let result = await group.next() {
results[result.0] = result.1
}
group.addTask { await (input.id, operation(input)) }
}
for await (id, result) in group {
results[id] = result
}
return results
}
}
Or if the input was Hashable, I might just use the input as the key to the dictionary:
@inlinable public func dictionaryWithTaskGroup<ChildTaskInput, ChildTaskResult>(
of childTaskResultType: ChildTaskResult.Type = ChildTaskResult.self,
isolation: isolated (any Actor)? = #isolation,
from array: [ChildTaskInput],
maxConcurrent: Int,
operation: sending @escaping @isolated(any) (ChildTaskInput) async -> ChildTaskResult
) async -> [ChildTaskInput: ChildTaskResult] where ChildTaskInput: Hashable, ChildTaskResult: Sendable {
await withTaskGroup(of: (ChildTaskInput, ChildTaskResult).self) { group in
precondition(maxConcurrent > 0)
var results: [ChildTaskInput: ChildTaskResult] = [:]
for (index, input) in array.enumerated() {
if index >= maxConcurrent, let result = await group.next() {
results[result.0] = result.1
}
group.addTask { await (input, operation(input)) }
}
for await (id, result) in group {
results[id] = result
}
return results
}
}
There are a bunch of ways of doing this, but hopefully this illustrates a few patterns for abstracting the “maximum concurrent tasks” logic out of our application code. Likewise, the above could be optimized/refined further, but I was trying to keep it simple for the sake of legibility.